转载自知乎:https://zhuanlan.zhihu.com/p/33162490
写在前面:
好久没有更新博客了,距离上一次更新已经过去了十一个月了,一是因为课业繁重,二是因为这一年中接了不少项目。其实早就想写写算法和数据结构相关的文章了,之前在Coders群里也说过17年要多写写算法和数据结构,奈何计划赶不上变化,实在是没有工夫写。现在到了18年了,最近刚放寒假,数据科学导论实验今天交上了最后一个,总算是有些闲工夫了,准备写些东西却又不知道应该写什么,算法那么多,从哪个写起呢?思来想去,想到了最短路径算法,因为博主今年开了计算机网络课程,在计算机网络中,有一个很重要的东西就是路由,即一个包怎么从某个节点发送到另外一个节点,在多条路径可供选择的时候,怎么选出来最佳路径,可以说,最短路算法是计算机网络的基石之一,本文就四种常规的最短路算法,及其原理,优化方法等进行了深入的介绍。
目录:
正文开始:
总述:
本文讲述的是求最短路的算法,首先就要定义最短路,严格的数学定义就不说了,我们用大白话说一说,在一个图G中,点u到点v有若干条路,那么定义u到v的最短路为这些路中最短的一条,这个是废话,显而易见。重要的是如果说边权中有负数怎么定义呢?如果有负边,就要分两种情况了。第一种情况:如果从某点出发,可以到达一个权值和为负数的环,那么这个点到其他点的最短距离就是负无穷了,很明显,如果有负环,且从某点可以到达这个负环,那么我可以无限得走这个负环,没走一次,距离就小一些,这种情况下,我们可以定义这个点到达其他点的最短距离为负无穷。第二种情况:如果说不存在一个这样的负环,那么就和没有负权边一样了,但是还不是完全一样,接下来我们介绍的四种算法中,有的是可以处理负权边不能处理负环的,有的是可以处理负环的,有的是既不能处理负权边也不能处理负环的。下面将会一一为您介绍。
约定:
文中的代码为部分代码,图为无向图,使用邻接矩阵a[][]存储, a[i][j]代表节点i到节点j的距离 若a[i][j]==Integer.MAX_VALUE>>1 则说明节点i和节点j不连通。文中算法以下面这个无向图为例说明。
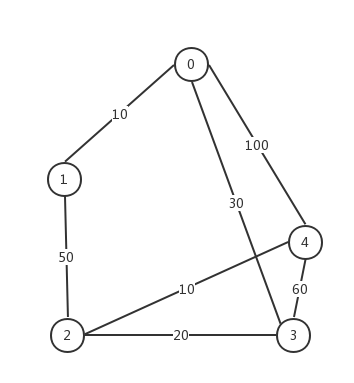
初始化代码:
private void init() {
n = 5;
a = new int[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
a[i][j] = Integer.MAX_VALUE >> 1;
}
a[i][i] = 0;
}
a[0][1] = 10;
a[1][0] = 10;
a[0][3] = 30;
a[3][0] = 30;
a[0][4] = 100;
a[4][0] = 100;
a[1][2] = 50;
a[2][1] = 50;
a[2][3] = 20;
a[3][2] = 20;
a[2][4] = 10;
a[4][2] = 10;
a[3][4] = 60;
a[4][3] = 60;
}Floyd:
首先介绍的是弗洛伊德算法,这个算法是一种基于动态规划的多源最短路算法。算法十分简洁优雅,代码如下:
private void floyd() {
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
a[i][j] = Math.min(a[i][j], a[i][k] + a[k][j]);
}
}
}
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
System.out.println(i + " " + j + ":" + a[i][j]);
}
}
}正确性分析:
核心代码只有四行,三行循环,一行更新,的确十分简洁优雅,博主在竞赛的时候遇到数据规模不大的题目时,经常偷懒用这个算法,可是这四行代码为什么就能求出任意两点的最短路径呢?看代码的特点,很显然特别像是一种动态规划,确实,之前也说过该算法是基于动态规划的。我们从动态规划的角度考虑,解动态规划题目的重点就是合理的定义状态,划分阶段,我们定义 f[k][i][j]为经过前k的节点,从i到j所能得到的最短路径,f[k][i][j]可以从f[k-1][i][j]转移过来,即不经过第k个节点,也可以从f[k-1][i][k]+f[k-1][k][j]转移过来,即经过第k个节点。观察一下这个状态的定义,满足不满足最优子结构和无后效性原则。
最优子结构:图结构中一个显而易见的定理:最短路径的子路径仍然是最短路径 ,这个定理显而易见,比如一条从a到e的最短路a->b->c->d->e 那么 a->b->c 一定是a到c的最短路c->d->e一定是c到e的最短路,反过来,如果说一条最短路必须要经过点k,那么i->k的最短路加上k->j的最短路一定是i->j 经过k的最短路,因此,最优子结构可以保证。
无后效性:状态f[k][i][j]由f[k-1][i][j],f[k-1][i,k] 以及f[k-1][k][j]转移过来,很容易可以看出,f[k] 的状态完全由f[k-1]转移过来,只要我们把k放倒最外层循环中,就能保证无后效性。
满足以上两个要求,我们即证明了Floyd算法是正确的。我们最后得出一个状态转移方程:f[k][i][j] = min(f[k-1][i][k],f[k-1][i][k],f[k-1][k][j]) ,可以观察到,这个三维的状态转移方程可以使用滚动数组进行优化。
滚动数组:
滚动数组是一种动态规划中常见的降维优化的方式,应用广泛(背包dp等),可以极大的减少空间复杂度。在我们求出的状态转移方程中,我们在更新f[k]层状态的时候,用到f[k-1]层的值,f[k-2] f[k-3]层的值就直接废弃了。所以我们大可让第一层的大小从n变成2,再进一步,我们在f[k]层更新f[k][i][j]的时候,f[k-1][i][k] 和 f[k-1][k][j] 我们如果能保证,在更新k层另外一组路径m->n的时候,不受前面更新过的f[k][i][j]的影响,就可以把第一维度去掉了。我们现在去掉第一个维度,写成我们在代码中的那样,就是f[i][j] 依赖 f[i][k] + f[k][j] 我们在更新f[m][n]的时候,用到了f[m][k] + f[k][n] 假设f[i][j]的更新影响到了f[m][k] 或者 f[k][m] 即 {m=i,k=j} 或者 {k=i,n=j} 这时候有两种情况,j和k是同一个点,或者i和k是同一个点,那么 f[i][j] = f[i][j] + f[j][j],或者f[i][j] = f[i][i]+f[i][j] 这时候,我们所谓的“前面更新的点对”还是这两个点本来的路径,也就是说,唯一两种在某一层先更新的点,影响到后更新的点的情况,是完全合理的,所以说,我们即时把第一维去掉,也满足无后效性原则。因此可以用滚动数组优化。优化之后的状态转移方程即为:f[i][j] = min(f[i][j],f[i][k]+f[k][j])。下面贴出在没有优化之前的代码:
int[][][] f = new int[n + 1][n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k <= n; k++) {
f[k][i][j] = Integer.MAX_VALUE >> 1;
}
f[0][i][j] = a[i][j];
}
}
for (int k = 1; k <= n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
f[k][i][j] = Math.min(f[k - 1][i][j], f[k - 1][i][k - 1] + f[k - 1][k - 1][j]);
}
}
}这里有必要解释一下,边界条件中,f[0][i][j] = a[i][j]因为在不经过任何一个点的时候,这两点的最短路径就是其初始路径,在Floyd过程中,最外层是从1开始的,状态转移方程也有点别扭,其实是因为我们一开始假设的点的标号是从0开始的,但是状态转移方程中第一维k代表前k个节点,由于Java中数组下标不能为-1,所以在第一维中,统一加上1,在更新的时候,还是通过k-1这个节点。
求具体路径:
我们上面仅仅是知道了最短路径的长度,实际应用中我们常常是需要知道具体的路径,在Floyd算法中怎么求具体路径呢,很简单,我们只需要记录下来在更新f[i][j]的时候,用到的中间节点是哪个就可以了。假设我们用path[i][j]记录从i到j松弛的节点k,那么从i到j,肯定是先从i到k,然后再从k到j, 那么我们在找出path[i][k] , path[k][j]即可,即 i到k的最短路是 i -> path[i][k] -> k -> path[k][j] -> k 然后求path[i][k]和path[k][j] ,一直到某两个节点没有中间节点为止,代码如下:
在更新路径的时候:
if(a[i][k]>temp){
a[i][j] = temp;
path[i][j] = k;
}求路径的时候:
public String getPath(int[][] path, int i, int j) {
if (path[i][j] == -1) {
return " "+i+" "+j;
} else {
int k = path[i][j];
return getPath(path, i, k)+" "+getPath(path, k, j)+" ";
}
}总结:
Floyd算法只能在不存在负权环的情况下使用,因为其并不能判断负权环,上面也说过,如果有负权环,那么最短路将无意义,因为我们可以不断走负权环,这样最短路径值便成为了负无穷。但是其可以处理带负权边但是无负权环的情况。以上就是求多源最短路的Floyd算法,基于动态规划,十分优雅。但是其复杂度确实是不敢恭维,因为要维护一个路径矩阵,因此空间复杂度达到了O(n^2),时间复杂度达到了O(n^3),只有在数据规模很小的时候,才适合使用这个算法,但是在实际的应用中,求单源最短路是最常见的,比如在路由算法中,某个节点仅需要知道从这个节点出发到达其他节点的最短路径,而不需要知道其他点的情况,因此在路由算法中最适合的应该是单源最短路算法,Dijkstra算法。
Dijkstra算法:
dijkstra算法是一种经典的基于贪心的单源最短路算法,其要求图中的边全部非负。
算法描述:
维护两个点集A,B,A点集代表已经求出源点到该点的最短路的点的集合,B代表未求出源点到该点的最短路径的点的集合。维护一个向量d,d[i]代表源点到点i的最短路径长度:不断进行以下操作:找出点集B中d[i] i∈B 最小的点,这个点为进入点集A的候选节点,然后通过该点松弛点集B中其他的点,更新向量d,然后将该候选点放入点集A,直到点集B为空。
算法正确性分析:
dijkstra算法基于贪心,贪心算法中最重要的一部分就是贪心策略,贪心算法对不对,就是贪心策略的正确不正确,在这个算法中,贪心策略就是,去寻找点i,满足min(d[i]) i∈B,满足这个条件的点i,必定是无法被继续松弛的点,如果说要松弛点i,那么必定通过A中或者B中的点进行更新,若通过B中的点j进行更新那么松弛之后的路径为d[j] + a[j][i] 由于d[i]已经是最小了,因此d[j]+a[j][i]>d[i] 因此不可能是通过B中的点进行松弛,若通过A中的点m进行松弛,由于m是点集A中的点,因此点m一定松弛过点i,重复的松弛没有意义的。因此,我们找到的点i,现在的d[i],一定是从源点到点i路径最小的点了,因此,该算法的正确性是可以保证的。
代码实现:
public void dijkstra(int p) {
int[] d = new int[n];
Set<Integer> set = new HashSet<>(n);
set.add(p);
for (int i = 0; i < n; i++) {
d[i] = a[p][i];
}
while (set.size() < n) {
int le = Integer.MAX_VALUE;
int num = 0;
for (int i = 0; i < n; i++) {
if (!set.contains(i) && le > d[i]) {
le = d[i];
num = i;
}
}
for (int i = 0; i < n; i++) {
if (!set.contains(i)) {
d[i] = Math.min(d[i], d[num] + a[num][i]);
}
}
set.add(num);
}
for (int i = 0; i < n; i++) {
System.out.println("点" + p + "到点" + i + "的距离为:" + d[i]);
}
}优先队列优化:
可以看出来,算法的时间复杂度为O(n),若通过这个算法求所有的点的最短路,即调用n次,那么算法复杂度为O(n^3)。那么这个算法能不能优化呢?不难看出来,算法中有两层循环,外层循环判断当前是否所有点都进入点集A,这一层是必要的,内层循环的主要功能就是找出来点集B中源点到其路径最短的点,这个地方显然可以使用优先队列进行优化。
我们知道常规的队列,是先进先出的线性表,优先队列即为,给每个进入队列的元素设置一个优先级,出队的时候,优先级最大的先出队,体现在dijkstra中就是,d[i]最小的优先级最大,实现优先队列的常用数据结构即堆,我们这里选取两种堆进行实现,一种是二叉小根堆,一种是斐波那契堆。下面介绍一下堆这种数据结构:
二叉堆:
堆是一种完全二叉树,我们以小根堆为例,小根堆的性质就是,每个节点都小于其左孩子和右孩子,不难发现,这种二叉树,根的值是最小的。堆有以下几种操作,堆的初始化,修改某个值(规定修改之后的值小于等于原来的值),插入某个值,取出根节点(即取出该优先队列中的优先级最高的值)。在进行这几种操作的时候,要维护堆的性质。
堆的存储:
我们不难发现以下结论:在一棵完全二叉树中,假设节点下标从0开始,那么点i的左孩子的下标为 (i<<1)+1 ,右孩子的下标为(i<<1)+2 ,父节点的下标为(i-1)>>1,我么可以使用数组来存储这棵完全二叉树。
向下调整:
向下调整即调整某个子树成为小根堆,由于小根堆的任意一个子树必定也是小根堆,当我们修改了位于i节点的某个值的时候,假设修改的值不小于原来的值,或者说修改的是根节点,那么如果要保持小根堆的性质,那么必定要判断这个节点是否需要移动,如果需要移动,那么必定是会移动到其子树中,不会向上移动。所以这时候就要将这个节点和它的两个孩子中的值较小的进行交换,由于完全二叉树的性质,右子树的深度总是小于等于左子树,所以为了这一小点优势,我们通常在两个孩子值相同时,和右孩子交换,然后这时候和他交换的这个孩子又需要调整了,显然也需要向下调整,因此我们递归调用向下调整,直到没有交换,或者到了叶子节点。这个操作的时间复杂度为O(lgn)。
向上调整:
向上调整和向下调整一样,适合将某个节点的值改为比以前更小或者相等的值,或者修改了叶子节点的情况。在这两种情况下,该节点需要向上移动,就是直接和这个节点的父节点比较,如果比父节点还小,那么就和他的父节点交换,然后递归向上调整它的父节点,直到到达根节点,或者某次没有交换。这个操作的复杂度也是O(lgn)。
初始化:
完全二叉树的一个显而易见的性质,假设其标号从0开始,到n-1结束,那么从n/2到n-1点全是叶子节点,叶子节点可以看成是节点数为1的堆,所以说我们如果要构建一个堆,就从(n/2)-1到0点进行向下调整即可。初始化的时间复杂度乍一看是O(nlogn),调整n/2次,每次复杂度是O(lgn),这不是O(nlogn)吗?其实不然,调整n/2次不假,但是并不是每次调整都是O(lgn),因为每次调整的复杂度取决于调整的子树的高度,因此,其复杂度小于O(nlgn),具体复杂度怎么算出来的这里不展开,详见《算法导论》P(88),这里只给出结论,初始化堆的时间复杂度为O(n)。
修改某个值:
假设把下标为i的节点的值改为了key(修改之后的值比之前的小,也就是优先级更高),那么如果要维护堆的性质,就要在该节点处向上调整。该操作的时间复杂度为O(lgn)
插入某个值:
将新节点插入到末尾,这个新节点必定是叶子节点,那么直接在这个节点上向上调整即可。该操作的时间复杂度为O(lgn)。
获取优先级最高的值(并删除):
由于二叉堆的性质,根节点的优先级必定是最高的(即节点的值最小)所以获取优先级最高的值只需要将根节点返回即可,如果要删除掉该节点,那么就将最后一个节点放到根节点的位置,然后从根节点处向下调整即可。该操作的时间复杂度为O(lgn)。
二叉堆的实现代码:
package shortestpath;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* Created by 王镜鑫 on 18-1-20.
* 请关注一下他的个人博客 wangjingxin.top
*
* @author 王镜鑫
*/
public class Heap<T extends Comparable<T>> {
//堆的规模
private int n;
//具体的堆
private List<T> a;
public Heap(T[] a) {
this.a = new ArrayList<>();
this.a.addAll(Arrays.asList(a));
this.n = this.a.size();
build();
}
/**
* 初始化堆
*/
public void build() {
for (int i = (n >> 1) - 1; i >= 0; i--) {
down(i);
}
}
/**
* 获取父节点的下标
* @param i
* @return
*/
private int parent(int i) {
return (i-1)>>1;
}
/**
* 获取左孩子的下标
* @param i
* @return
*/
public int left(int i) {
return (i << 1) + 1;
}
/**
* 获取右孩子的下标
* @param i
* @return
*/
public int right(int i) {
return (i << 1) + 2;
}
/**
* 向下调整
* @param i
*/
public void down(int i) {
int left = left(i);
int right = right(i);
int small = i;
if (left < n && a.get(left).compareTo(a.get(i)) < 0) {
small = left;
}
if (right < n && a.get(right).compareTo(a.get(small)) < 0) {
small = right;
}
if (small != i) {
T temp = a.get(i);
a.set(i, a.get(small));
a.set(small, temp);
down(small);
}
}
/**
* 向上调整
* @param i
*/
public void up(int i) {
int parent = parent(i);
if (parent >= 0 && a.get(parent).compareTo(a.get(i)) > 0) {
T temp = a.get(i);
a.set(i, a.get(parent));
a.set(parent, temp);
up(parent);
}
}
/**
* 将下标为i处的节点值更新为key
* @param i
* @param key
*/
public void update(int i, T key) {
a.set(i, key);
up(i);
}
/**
* 插入新的节点key
* @param key
*/
public void insert(T key) {
a.add(key);
n++;
up(n - 1);
}
/**
* 获取并移除根节点
* @return
*/
public T getTop() {
T result = a.get(0);
a.set(0, a.get(--n));
down(0);
return result;
}
@Override
public String toString() {
return a.toString();
}
public static void main(String[] args) {
Integer[] a = {16, 4, 10, 14, 7, 9, 3, 2, 8, 1};
Heap<Integer> heap = new Heap<>(a);
System.out.println(heap);
heap.insert(13);
System.out.println(heap);
heap.update(3, 1);
System.out.println(heap);
}
} 使用二叉堆优化Dijkstra:
在常规的Dijkstra算法中,有一个查找当前B点集中d[i]最小的节点,这个地方我们可以使用优先队列进行优化,一开始将所有的点除了源点之外,放到二叉堆中,然后查找节点i的时候,直接调用getTop方法,时间复杂度为O(lgn),由于对每个节点调用一次,因此总共需要n次这个操作,在获取到点i之后,通过点i进行松弛,松弛之后需要更新该节点,因此需要调用update方法,需要松弛的其实并非所有节点,而只是点i的临接点。因此,update操作需要调用E(图中边的数量)次,因此,使用二叉堆优化后的Dijkstra算法的复杂度为O((E+n)lgn),因此该优化适合于稀疏图,如果是稠密图极端情况E = n*(n-1)/2,这时候时间复杂度就退化为O(n^2logn)了,的确是得不偿失。
二叉堆优化后的Dijkstra代码:
public void dijkstraWithBinaryHeap(int p) {
Node[] nodes = new Node[n-1];
int index = 0;
for(int i=0;i<n;i++){
if(i!=p){
nodes[index++] = new Node(a[p][i],i);
}
}
Heap<Node> heap = new Heap<>(nodes);
int count = 1;
int[] result = new int[n];
while (count<n){
count++;
Node node = heap.getTop(); //获取优先级最高的
result[node.i] = node.key;
List<Node> list = heap.list();
for(int i=0;i<list.size();i++){
Node n = list.get(i);
if(n.key>node.key+a[node.i][n.i]){
n.key = node.key+a[node.i][n.i];
heap.update(i,n);
}
}
}
for (int i = p + 1; i < n; i++) {
System.out.println("点" + p + "到点" + i + "的距离为:" + result[i]);
}
}在堆中存储节点信息的时候,博主新增了一个Node类,存储了该节点的标号以及源点到他的距离,类如下:
static class Node implements Comparable<Node> {
private int key; //源点到该点的距离
private int i; //该点的下标
public Node(int key,int i){
this.key = key;
this.i = i;
}
@Override
public int compareTo(Node o) {
return this.key - o.key;
}
}在松弛点的时候,博主是直接遍历的整个堆。所以给堆提供了一个遍历的方法,代码如下:
public List<T> list(){
return a.subList(0,n);
}其实在松弛点的时候,可以只遍历node点的邻接点,可是这样在更新堆中的节点的时候就有问题了,因为我们需要知道该点在堆中的位置,我们可以在Node类中新加一个属性,代表现在该点在堆中的位置,然后在向上向下调整的时候,去维护这个属性即可。
到现在,我们使用二叉堆优化Dijkstra算法使其复杂度变成了O((n+E)lgn)然而这个只是在稀疏图下可以看出优化效果,在稠密图中,这样的优化甚至比优化之前效果更差,事实上,我们可以使用另一种优先队列使其优化到O(nlgn+V)。
斐波那契堆:
这个数据结构相对来说比较复杂,关于斐波那契堆的介绍和Dijkstra的斐波那契堆优化在后续文章中给出。
总结:
Dijkstra算法是一种优秀的经典的最短路算法,在优先队列的优化下,它的时间复杂度也是可接受的,它在计算机网络等应用中广泛存在,然而他也有他的局限性,它的局限性甚至比Floyd算法都要大,Floyd算法允许有负权边,不允许有负权环,Dijkstra算法连负权边都不允许,因为Dijkstra的正确性基于以下假设:当前未找到最短路的点中,距离源点最短的那个点,无法继续被松弛,这时候他肯定是已经松弛到最短状态了。但是这个假设在有负权边的时候就不成立了,举一个经典例子:一个具有三个点三条边的图,0->1距离为2,0->2距离为3,2->1距离为-2,根据Dijkstra算法,我们第一次肯定会将节点1加入到已经松弛好的点集中,但是这时候是不对的,2并不是0->1最短的路径,而通过点2松弛过的路径:0->2->1才是最短的路径,因为负权边的存在,我们认为的已经被松弛好的点,在未来还有被松弛的可能。这个就是Dijkstra的局限性,然而这并不影响它的伟大,因为在实际应用中,没有负权的图是更为常见的。但是我们仍然需要可以处理负权,甚至负环的算法,这时候Bellman-Ford算法和SPFA算法就派上用场了。
Bellman-Ford和SPFA:
这个算法就是大名鼎鼎的贝尔曼福特算法,这个算法是最常规下的单源最短路问题,对边的情况没有要求,不仅可以处理负权边,还能处理负环。可谓是来者不拒。
算法描述:
对于一个图G(v,e)(v代表点集,e代表边集),执行|v|-1次边集的松弛操作,所谓松弛操作,就是对于每个边e1(v,w),将源点到w的距离更新为:原来源点到w的距离 和 源点到v的距离加上v到w的距离 中较小的那个。v-1轮松弛操作之后,判断是否有源点能到达的负环,判断的方法就是,再执行一次边集的松弛操作,如果这一轮松弛操作,有松弛成功的边,那么就说明图中有负环。算法复杂度为O(ne)
代码实现:
一个方法,返回一个bool值,bool值为true则图中没有源点可达的负环,false即为图中有源点可达的负环。
public boolean bellmanFord(int s){
int[] d = new int[n];
for(int i=0;i<n;i++){
d[i] = a[s][i];
}
for(int i=0;i<n-1;i++){
for(int j=0;j<n;j++){
for(int k=0;k<n;k++){
if(a[j][k]!=Integer.MAX_VALUE){
d[k] = Math.min(d[k],d[j]+a[j][k]);
}
}
}
}
for(int j=0;j<n;j++) {
for (int k = 0; k < n; k++) {
if (a[j][k] != Integer.MAX_VALUE) {
if(d[k]>d[j]+a[j][k]){
return false;
}
}
}
}代码中的边的松弛操作中,博主是遍历的整个邻接矩阵,判断是否两点间存在边,如果存在,则进行松弛操作。其实这个地方可以存一份边集,新建一个类类中有两个属性,start和end,代表某条边的两个端点,初始化图的时候,构造出来所有的边,存储在一个集合中。在进行Bellman-Ford的时候,直接遍历这个边集即可,免去了额外的判断。
正确性分析:
看起来很神奇,我们只要松弛n-1次松弛操作,就能得到源点到各个点的最短路径。其实,这里面是有科学道理的,在子弹出膛的瞬间,急速抖动手腕,给子弹一个初速度,这就是枪斗术。(开个玩笑)想要证明这个算法的正确性,就要好好说一说这个松弛操作,我们约定d[i]为源点到点i的当前的最短距离,松弛操作有一个重要的性质,被称为路径松弛性质:假设p=(v0,v1…vk)是从源点s到目标节点vk的一条最短路径,并且我们对p中的边进行松弛操作的顺序为(v0,v1) (v1,v2)…(vk-1,vk),那么这些松弛操作结束之后的d[k],必是源点s到点k的最短路长度,该性质的成立,与其他的松弛操作无关,即时其他的松弛操作在对p边上的松弛操作穿插进行的。下面我们就来证明一下这个性质,使用数学归纳法:
路径松弛性质证明:
定义:f(v)为源点s到点v的最短路径长度,d[i]为源点到点i的当前的最短距离。
如果要证明这个性质,必须先知道有以下性质:
松弛操作的收敛性质:对于节点u,v∈V,如果s->….->…->u->v为一条s到v的最短路,且在对边(u,v)进行松弛操作之前有f[u] = d[u],则必有:在对边(u,v)松弛之后f[v] = d[v]。这个定理读者自行体会,不再给出证明。
定义:p为源点到点vk的一条最短路,vi代表p中第i条边的结束节点,我们使用数学归纳法证明:
归纳假设:最短路p的第i条边被松弛之后d[vi] = f[vi]。
i=0:在i=0的时候,也就是第0条边被松弛的时候,很显然,在我们初始化d的时候,d[s] = f[0] = 0
归纳:假设d[vi-1] = f[vi-1]成立,根据松弛操作的收敛性质,在对边(vi-1,vi)进行松弛之后,满足,f[vi] = d[vi]
证明结束。
已知该性质证明算法的正确性:
没有负环的情况:我们现在已经证明了路径松弛性质,那么显而易见,在没有负环的时候,一个图中的两个节点s,u的最短路径v0->v1,v1->v2,…..vk-1->vk为简单路径(即没有环的路径),所以对于节点数目为|V|的图,s,u的最短路径,最多有|V|-1条边,即k<=|V|-1。我们在算法中,一共进行了|V|-1次所有边的松弛操作,因为每次对所有的边进行松弛,所以对于最短路中第i条路径vi-1->vi,一定在第i次松弛操作中被松弛了,那么根据松弛路径性质,在进行|V|-1次所有边的松弛操作之后,毕竟得到所有点的最短路径。
负环的判断:如果有源点可达的负环,说明源点到某点的最短路径不是简单路径(不断走负环达到负无穷),因此在第|V|次松弛的时候,还能被松弛,因此在第|V|次松弛的时候,还能被松弛,就说明有负环存在。
优化(SPFA):
Bellman-Ford算法虽然可以处理负环,但是时间复杂度为O(ne),e为图的边数,在图为稠密图的时候,是不可接受的。复杂度太高。我们分析一下能不能进行优化,Bellman-Ford算法的正确性保证依赖于路径松弛性质,我们只要能够保证最短路径中的边的松弛顺序即可,Bellman-Ford算法属于一种暴力的算法,即,每次将所有的边都松弛一遍,这样肯定能保证顺序,但是仔细分析不难发现,源点s到达其他的点的最短路径中的第一条边,必定是源点s与s的邻接点相连的边,因此,第一次松弛,我们只需要将这些边松弛一下即可。第二条边必定是第一次松弛的时候的邻接点与这些邻接点的邻接点相连的边(这句话是SPFA算法的关键,请读者自行体会),因此我们可以这样进行优化:设置一个队列,初始的时候将源点s放入,然后s出队,松弛s与其邻接点相连的边,将松弛成功的点放入队列中,然后再次取出队列中的点,松弛该点与该点的邻接点相连的边,如果松弛成功,看这个邻接点是否在队列中,没有则进入,有则不管,这里要说明一下,如果发现某点u的邻接点v已经在队列中,那么将点v再次放到队列中是没有意义的。因为即时你不放入队列中,点v的邻接点相连的边也会被松弛,只有松弛成功的边相连的邻接点,且这个点没有在队列中,这时候稍后对其进行松弛才有意义。因为该点已经更新,需要重新松弛。
SPFA代码实现:
public void spfa(int s){
Queue<Integer> queue = new ArrayDeque<>(n);
int[] d = new int[n];
boolean[] flag = new boolean[n];
for(int i=0;i<n;i++){
d[i] = Integer.MAX_VALUE;
flag[i] = false;
}
d[s] = 0;
queue.add(s);
flag[s] = true;
Integer u;
while ((u=queue.poll())!=null){
flag[u] = false;
for(int i=0;i<n;i++){
if(a[u][i]!=Integer.MAX_VALUE>>1){
int temp = d[u] + a[u][i];
if(temp<d[i]){
d[i] = temp;
if(!flag[i]){
queue.add(i);
flag[i] = true;
}
}
}
}
}
for (int i = s + 1; i < n; i++) {
System.out.println("点" + s + "到点" + i + "的距离为:" + d[i]);
}
}还是那样,博主并没有使用邻接表来存储图,使用Bellman-Ford算法和SPFA算法适合结合邻接表来存储图。
总结:
Bellman-Ford算法和SPFA算法,都是基于松弛操作,以及路径松弛性质的,不同之处在于,前者是一种很暴力的算法,为了保证顺序,每次把所有的边都松弛一遍,复杂度很高,而后者SPFA,则是在Bellman-Ford算法的基础上进行了剪枝优化,只松弛那些可能是下一条路径的边,但是关于SPFA算法的复杂度,现在还没有个定论,不过达成的共识是:算法的时间复杂度为O(me),其中m为入队的平均次数,其发明者,西安交大的段凡丁大神的论文中,m是一个常数(这个结论是错的),我们“姑且”认为该算法的时间复杂度为O(e)【滑稽】,的确该算法的效率是很高的,博主在oi中经常使用这个算法,除非题目数据特意卡SPFA。或者的确是稠密图,一般情况下不会超时。关于其判断负环,我们可以认为,在某个节点入队次数达到n的时候,就可以说明遇到了负环。SPFA有两个优化策略:SLF:Small Label First 策略,设要加入队列的节点是j,队首元素为i,若d[j]<dist[i],则将j插入队首,否则插入队尾; LLL:Large Label Last 策略,设队首元素为i,队列中所有d值的平均值为x,若d[i]>x则将i插入到队尾,查找下一元素,直到找到某一i使d[i]<=x,则将i出队进行松弛操作。其实,实际应用中,SPFA的时间复杂度是很不稳定的,因此我们能用Dijkstra+优先队列,就用Dijkstra+优先队列为好。
总结:
本文中,我们介绍了三种最短路算法(Dijkstra和Bellman-Ford的求具体路径方法读者自行考虑),Floyd,Dijkstra,Bellman-Ford,以及Bellman-Ford的队列优化SPFA,从原理,正确性以及优化上作了“深入分析”(假装很深入),自认为讲的还算清晰透彻。博主写这一篇文章,大约前前后花了有一天的时间。其中大部分都是晚上写的,由于时间精力有限,晚上深夜的时候精力也不是很足,所以难免有疏漏,欢迎各位看客指正,提出意见或者建议。发到评论区即可。文章中关于斐波那契堆优化的部分没有讲,博主会在后期再写一篇文章专门来讲这部分内容。如果你感觉本篇文章对你有帮助,那么就资助一下博主吧!感谢各位!
0.0分
2 人评分
C语言网提供由在职研发工程师或ACM蓝桥杯竞赛优秀选手录制的视频教程,并配有习题和答疑,点击了解:
一点编程也不会写的:零基础C语言学练课程
解决困扰你多年的C语言疑难杂症特性的C语言进阶课程
从零到写出一个爬虫的Python编程课程
只会语法写不出代码?手把手带你写100个编程真题的编程百练课程
信息学奥赛或C++选手的 必学C++课程
蓝桥杯ACM、信息学奥赛的必学课程:算法竞赛课入门课程
手把手讲解近五年真题的蓝桥杯辅导课程

发表评论 取消回复